Beyond the Prompt: Hunting for NIST Gaps with Local LLMs
The Problem Nobody Wants to Talk About
Here's a dirty secret about enterprise security: most organizations have policies. They just don't know if those policies are any good.
Not because the policies are badly written, often they're meticulous, dense, and authored by people who clearly know their stuff. The problem is the gaps. Subtle, easy-to-miss holes that an auditor, or an attacker, can walk right through.
Answering that question manually means hiring a certified auditor, blocking out 30+ hours of their time, and paying somewhere around $500/hour while they highlight PDFs in silence. For every policy. Every year.
That's the world we were handed for this hackathon, and the constraint that made it genuinely interesting: no cloud, no internet, no external APIs. Whatever we built had to run entirely on a laptop.
The First Attempt That Didn't Work
We fed the policy into an LLM with a big prompt asking for a gap analysis against the NIST Cybersecurity Framework, and waited for magic.
The magic did not arrive.
What we got was vague, repetitive, and, most damning, the model quietly stopped caring about the later sections of a long document. For a 50-page policy, that meant about 35 pages of analysis that was really just confident-sounding guesswork. The output looked right but wasn't something you could act on.
So we scrapped it and started thinking like engineers instead of prompt engineers.
The Insight: Stop Chatting, Start Pipelining
The shift in mindset that saved us was this: the LLM isn't a black box oracle. It's a reasoning primitive. Build a pipeline around it.
Instead of asking one model to do everything, we broke the problem into stages where each LLM call had a small, well-defined job. The model's unreliability on long contexts became manageable when we could validate, correct, and retry at each step.
We switched to Gemma 4 (2B parameters), small enough to run on a laptop, but surprisingly capable for structured tasks when you scope each call correctly.
Phase 1: Teaching the Machine to Read
PDFs are where structure goes to die. Even after converting to markdown with Docling (which handles the malformed font encodings that plague scanned policy docs), you're left with a wall of text. The model needs to understand sections before it can reason about coverage.
Our first instinct was to ask the LLM to re-structure the document. Bad idea. It started dropping clauses, reordering sentences, and quietly rewriting things that were already correct. For a compliance document, that's unacceptable, the original language has to stay intact.
So we flipped it: ask the model to identify line numbers only, then use deterministic Python to pull the text.
We built an Extractor → Validator → Corrector loop. The Extractor finds section boundaries. The Validator checks whether those boundaries actually align with headings in the source text, and whether sections overlap or leave gaps. If the Validator finds problems, the Corrector reruns the extraction with the specific failures highlighted.
The LLM reasons about structure. Python handles the actual text retrieval. No hallucinations can sneak into the content that way.
Phase 2: The Fire Suppression Problem
Here's a thing nobody mentions in compliance tooling discussions: not every control belongs in every policy.
If you audit an Access Control policy against the full NIST CSF, you'll find it "missing" things like fire suppression procedures, backup power requirements, and physical access logging. Those aren't gaps, they're different documents. Flagging them as gaps creates noise that trains security teams to ignore your tool.
We called this the Fire Suppression Problem, and solving it was arguably the most important design decision we made.
Before running any gap analysis, our Scope Classifier reads the policy and builds an explicit allow-list: which NIST functions and subcategories are actually in scope for this document? An Access Control policy gets Protect/Access Control, Protect/Identity Management, maybe parts of Govern. It does not get Physical Security.
With scoping done, the analysis runs a Map-Reduce across every in-scope NIST subcategory. Map phase: scan each section for evidence related to the subcategory. Reduce phase: consolidate that evidence and make one verdict: Addressed, Partially Addressed, Not Addressed, or Out of Scope, with specific quotes from the policy as proof.
Every gap finding has a citation. Every recommendation is traceable to a NIST subcategory. Nothing is hand-wavy.
Phase 3: Writing Fixes That Don't Sound Like a Robot Wrote Them
Finding gaps is half the problem. The other half is actually fixing the policy, and doing it in a way that doesn't make the document read like it was stapled together from two different authors.
We used an approach we called RAPTOR + CoVe: Recursive Abstractive Processing for summaries (to give the model context about the overall policy structure), combined with Chain-of-Verification (to make the model check its own work before we accept it).
The key constraint: we never let the LLM rewrite existing sections wholesale. We only let it generate "delta blocks", small, targeted additions that address a specific gap. The model then has to explicitly verify: does this addition satisfy the NIST requirement, or is it just plausible-sounding filler?
Only after that self-check passes does the block get integrated back into the original text. The result reads like the original author came back and filled in what was missing, because the original author's voice is preserved everywhere the model didn't touch.
Every run produces a revised report showing exactly what was added, where, and why. Full traceability.

Does It Actually Work?
We ran the pipeline against six real policy types — ISMS, Incident Response, Access Control, Patch Management, Data Privacy & Security, and Risk Management — benchmarking gap detection accuracy across all 106 NIST CSF subcategories per policy.
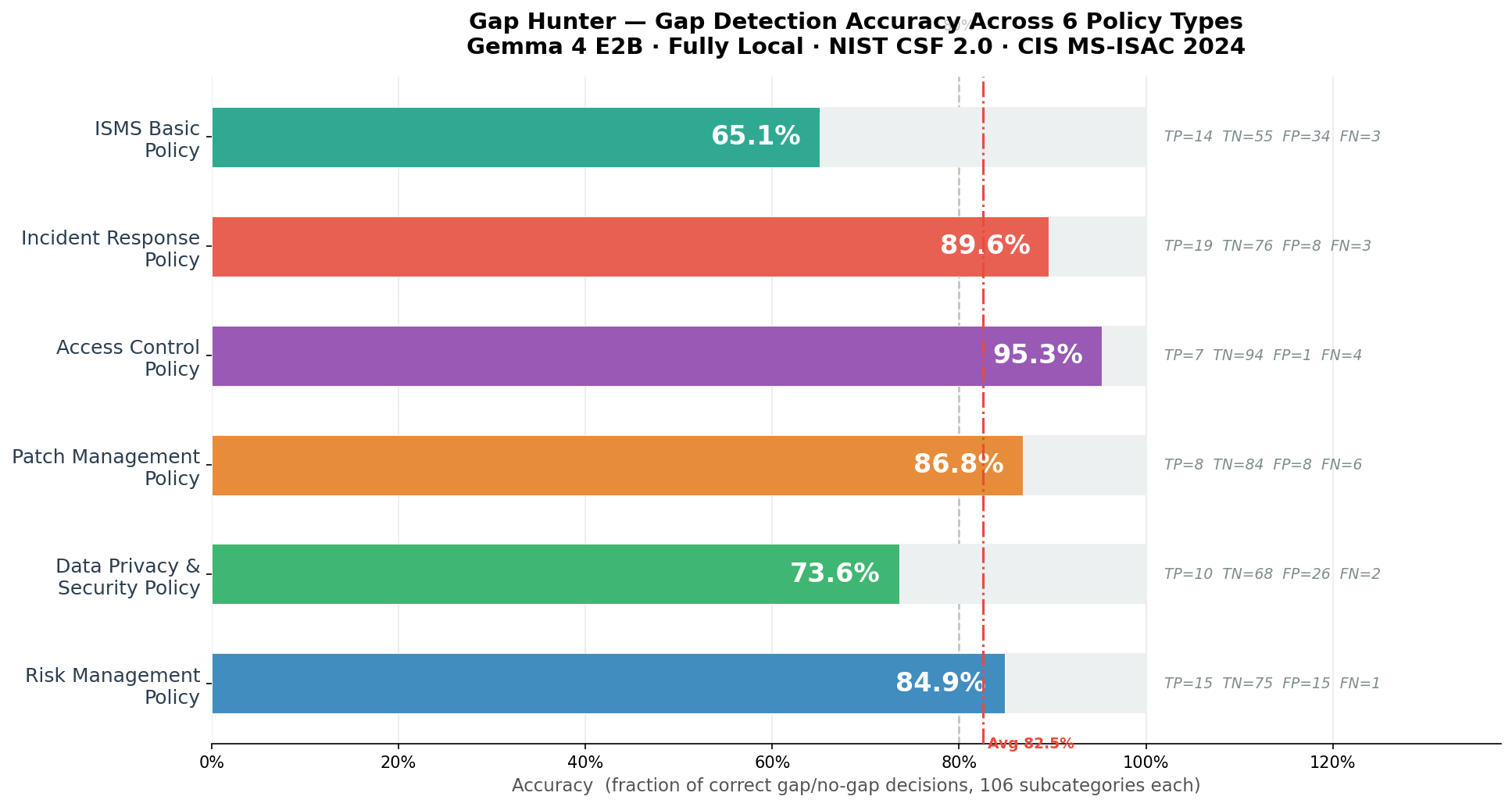
The average accuracy landed at 82.5%, with Access Control hitting 95.3% and Incident Response at 89.6%. The weakest result was ISMS Basic Policy at 65.1% — unsurprisingly, ISMS is the broadest policy type, covering the most ground, which makes scoping harder and false positives more likely.
The false positive pattern is telling: most FPs came from subcategories the Scope Classifier correctly excluded but where the policy had adjacent language that looked relevant. That's a calibration problem, not a reasoning problem, and it's fixable.
What We Actually Learned
Three things surprised us by the end of the hackathon:
Small models are underrated for structured tasks. Gemma 4 at 2B parameters, with the right context window and prompt architecture, can produce reliable structured output for reasoning tasks. The trick isn't model size, it's reducing the cognitive load of each individual call.
Validation beats correction. Every time we added a validation step, we caught more problems than we expected. The Extractor-Validator-Corrector pattern added complexity but massively improved output quality. The validator's job is easier than the extractor's, which makes it a cheap safety net.
The pipeline is the product. We spent most of our time on orchestration, designing the data flow, what each stage receives, what it's allowed to produce, where humans should review before the next stage runs. The prompts and the pipeline both matter; neither works without the other.
With the right orchestration, deterministic guardrails, well-scoped LLM calls, and validated outputs at every stage, a 2B-parameter model running offline on a laptop can produce output that would take a human expert days to generate.
Access full source from here.